Guide to tidy git analysis
@drsimonj here to help you embark on git repo analyses!
Ever wondered who contributes to git repos? How their contributions have changed over time? What sort of conventions different authors use in their commit messages? Maybe you were inspired by Mara Averick to contribute to tidyverse packages and wonder how you fit in?
This post – intended for intermediate R users – will help you answer these sorts of questions using tidy R tools.
Install and load these packages to follow along:
# Parts 1 and 2
library(tidyverse)
library(glue)
library(stringr)
library(forcats)
# Part 3
library(tidygraph)
library(ggraph)
library(tidytext)
Part 1: Git repo to a tidy data frame #
Get a git repo #
We’ll explore the open-source ggplot2 repo by copying it to our local machine with git clone, typically run on a command-line like:
git clone <repository_url> <directory>
Find the <repository_url> for github.com projects by clicking “Clone or download”.
<directory> is optional but useful for us to clone into a specific location.
The R code below clones the ggplot2 git repo into a temporary directory called "git_repo" (let Alexander Matrunich teach you more about temp directories and files here). system() invokes these commands from R (instead of using a command-line directly) and the glue package beautifully handles the strings for us.
# Remote repository URL
repo_url <- "https://github.com/tidyverse/ggplot2.git"
# Directory into which git repo will be cloned
clone_dir <- file.path(tempdir(), "git_repo")
# Create command
clone_cmd <- glue("git clone {repo_url} {clone_dir}")
# Invoke command
system(clone_cmd)
Check the directory contents:
list.files(clone_dir)
#> [1] "_pkgdown.yml" "appveyor.yml" "codecov.yml"
#> [4] "CONTRIBUTING.md" "cran-comments.md" "data"
#> [7] "data-raw" "DESCRIPTION" "ggplot2.Rproj"
#> [10] "icons" "inst" "ISSUE_TEMPLATE.md"
#> [13] "LICENSE" "man" "NAMESPACE"
#> [16] "NEWS" "NEWS.md" "R"
#> [19] "README.md" "README.Rmd" "revdep"
#> [22] "tests" "vignettes"
Get tidy git history #
You can now access the git history of the local repo using git log (making sure to target the right directory with -C). Examine the last few commits via:
system(glue('git -C {clone_dir} log -3'))
#> commit 3c9c504fdb2f2c6b70a98d5a02f6cdf2c8cc62c9
#> Merge: cab8a54e 449bc039
#> Author: Lionel Henry <lionel.hry@gmail.com>
#> Date: Thu Mar 22 18:42:25 2018 +0100
#>
#> Merge pull request #2491 from tidyverse/tidyeval-facets
#>
#> Port facets to tidy eval
#>
#> commit 449bc039a75dd06e0ff52233c5d747f81b4d7c30
#> Author: Lionel Henry <lionel.hry@gmail.com>
#> Date: Thu Mar 22 17:54:12 2018 +0100
#>
#> Remove dependency on plyr::as.quoted()
#>
#> commit dc3c9855fd18f78ba8ef14d7e485334ac47e3b16
#> Author: Lionel Henry <lionel.hry@gmail.com>
#> Date: Thu Mar 22 16:39:12 2018 +0100
#>
#> Call formula interface classic instead of historical
This default output is nice but difficult to parse. Fortunately, git log has the --pretty option, which the code below uses to create a command to return nicely formatted logs (learn more about log formatting here):
log_format_options <- c(datetime = "cd", commit = "h", parents = "p", author = "an", subject = "s")
option_delim <- "\t"
log_format <- glue("%{log_format_options}") %>% collapse(option_delim)
log_options <- glue('--pretty=format:"{log_format}" --date=format:"%Y-%m-%d %H:%M:%S"')
log_cmd <- glue('git -C {clone_dir} log {log_options}')
log_cmd
#> git -C /var/folders/f3/0qlt4tvx7lld3r1wx8q6z9gnrc2yg8/T//RtmpHj21yK/git_repo log --pretty=format:"%cd %h %p %an %s" --date=format:"%Y-%m-%d %H:%M:%S"
This outputs each commit as a string of tab-separated values:
system(glue('{log_cmd} -3'))
#> 2018-03-22 18:42:25 3c9c504f cab8a54e 449bc039 Lionel Henry Merge pull request #2491 from tidyverse/tidyeval-facets
#> 2018-03-22 17:55:23 449bc039 dc3c9855 Lionel Henry Remove dependency on plyr::as.quoted()
#> 2018-03-22 17:55:23 dc3c9855 1182b9f3 Lionel Henry Call formula interface classic instead of historical
The R code below executes this for the entire repo, captures the output (via intern = TRUE), splits commit strings into vectors of values (thanks to stringr), and converts them to a named tibble.
history_logs <- system(log_cmd, intern = TRUE) %>%
str_split_fixed(option_delim, length(log_format_options)) %>%
as_tibble() %>%
setNames(names(log_format_options))
history_logs
#> # A tibble: 3,946 x 5
#> datetime commit parents author subject
#> <chr> <chr> <chr> <chr> <chr>
#> 1 2018-03-22 18:42:25 3c9c504f cab8a54e 449bc039 Lionel Henry Merge pull…
#> 2 2018-03-22 17:55:23 449bc039 dc3c9855 Lionel Henry Remove dep…
#> 3 2018-03-22 17:55:23 dc3c9855 1182b9f3 Lionel Henry Call formu…
#> 4 2018-03-22 17:55:23 1182b9f3 b2144a8e Lionel Henry Document t…
#> 5 2018-03-22 17:55:23 b2144a8e 13db76d2 Lionel Henry Mention ti…
#> 6 2018-03-22 17:55:23 13db76d2 95253c66 Lionel Henry Accept var…
#> 7 2018-03-22 17:55:23 95253c66 2983aa0d Lionel Henry Accept var…
#> 8 2018-03-22 17:55:23 2983aa0d 64a00c7d Lionel Henry Rename as_…
#> 9 2018-03-22 17:55:23 64a00c7d f186615a Lionel Henry Use proper…
#> 10 2018-03-22 17:55:23 f186615a cab8a54e Lionel Henry Support qu…
#> # ... with 3,936 more rows
The entire git commit history is now a tidy data frame (tibble)! We’ll finish this section with two minor additions.
First, the parents column can contain space-separated strings when a commit was a merge of multiple, for example. The code below converts this to a list-column of character vectors (let Jenny Bryan teach you more about this here):
history_logs <- history_logs %>%
mutate(parents = str_split(parents, " "))
history_logs
#> # A tibble: 3,946 x 5
#> datetime commit parents author subject
#> <chr> <chr> <list> <chr> <chr>
#> 1 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry Merge pull request…
#> 2 2018-03-22 17:55:23 449bc039 <chr [1]> Lionel Henry Remove dependency …
#> 3 2018-03-22 17:55:23 dc3c9855 <chr [1]> Lionel Henry Call formula inter…
#> 4 2018-03-22 17:55:23 1182b9f3 <chr [1]> Lionel Henry Document tidy eval…
#> 5 2018-03-22 17:55:23 b2144a8e <chr [1]> Lionel Henry Mention tidy eval …
#> 6 2018-03-22 17:55:23 13db76d2 <chr [1]> Lionel Henry Accept vars() spec…
#> 7 2018-03-22 17:55:23 95253c66 <chr [1]> Lionel Henry Accept vars() spec…
#> 8 2018-03-22 17:55:23 2983aa0d <chr [1]> Lionel Henry Rename as_facets_s…
#> 9 2018-03-22 17:55:23 64a00c7d <chr [1]> Lionel Henry Use proper quosure…
#> 10 2018-03-22 17:55:23 f186615a <chr [1]> Lionel Henry Support quosures i…
#> # ... with 3,936 more rows
Finally, be sure to assign branch numbers to commits. There’s surely a better way to do this, but here’s one (very untidy) method:
# Start with NA
history_logs <- history_logs %>% mutate(branch = NA_integer_)
# Create a boolean vector to represent free columns (1000 should be plenty!)
free_col <- rep(TRUE, 1000)
for (i in seq_len(nrow(history_logs) - 1)) { # - 1 to ignore root
# Check current branch col and assign open col if NA
branch <- history_logs$branch[i]
if (is.na(branch)) {
branch <- which.max(free_col)
free_col[branch] <- FALSE
history_logs$branch[i] <- branch
}
# Go through parents
parents <- history_logs$parents[[i]]
for (p in parents) {
parent_col <- history_logs$branch[history_logs$commit == p]
# If col is missing, assign it to same branch (if first parent) or new
# branch (if other)
if (is.na(parent_col)) {
parent_col <- if_else(p == parents[1], branch, which.max(free_col))
# If NOT missing this means a split has occurred. Assign parent the lowest
# and re-open both cols (parent closed at the end)
} else {
free_col[c(branch, parent_col)] <- TRUE
parent_col <- min(branch, parent_col)
}
# Close parent col and assign
free_col[parent_col] <- FALSE
history_logs$branch[history_logs$commit == p] <- parent_col
}
}
We now also have branch values with 1 being the root.
history_logs
#> # A tibble: 3,946 x 6
#> datetime commit parents author subject branch
#> <chr> <chr> <list> <chr> <chr> <int>
#> 1 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry Merge pull … 1
#> 2 2018-03-22 17:55:23 449bc039 <chr [1]> Lionel Henry Remove depe… 2
#> 3 2018-03-22 17:55:23 dc3c9855 <chr [1]> Lionel Henry Call formul… 2
#> 4 2018-03-22 17:55:23 1182b9f3 <chr [1]> Lionel Henry Document ti… 2
#> 5 2018-03-22 17:55:23 b2144a8e <chr [1]> Lionel Henry Mention tid… 2
#> 6 2018-03-22 17:55:23 13db76d2 <chr [1]> Lionel Henry Accept vars… 2
#> 7 2018-03-22 17:55:23 95253c66 <chr [1]> Lionel Henry Accept vars… 2
#> 8 2018-03-22 17:55:23 2983aa0d <chr [1]> Lionel Henry Rename as_f… 2
#> 9 2018-03-22 17:55:23 64a00c7d <chr [1]> Lionel Henry Use proper … 2
#> 10 2018-03-22 17:55:23 f186615a <chr [1]> Lionel Henry Support quo… 2
#> # ... with 3,936 more rows
This rounds off the section on getting a git commit history into a tidy data frame. Remove the local git repo, which is no longer needed:
unlink(clone_dir, recursive = TRUE)
Part 2: Tidy Analysis #
You’re now ready to embark on a tidy git repo analysis! For example, which authors make the most commits?
history_logs %>%
count(author, sort = TRUE)
#> # A tibble: 165 x 2
#> author n
#> <chr> <int>
#> 1 hadley 2285
#> 2 Winston Chang 650
#> 3 Hadley Wickham 104
#> 4 Kohske Takahashi @ jurina 103
#> 5 Kohske Takahashi at Haruna 70
#> 6 hadley wickham 69
#> 7 Jean-Olivier Irisson 63
#> 8 Lionel Henry 50
#> 9 Thomas Lin Pedersen 47
#> 10 Kirill Müller 40
#> # ... with 155 more rows
Some authors appear under different names, which we can quickly correct based on these top cases:
history_logs <- history_logs %>%
mutate(author = case_when(
str_detect(tolower(author), "hadley") ~ "Hadley Wickham",
str_detect(tolower(author), "kohske takahashi") ~ "Kohske Takahashi",
TRUE ~ str_to_title(author)
))
Now, again, authors by commit frequency:
history_logs %>%
count(author) %>%
arrange(desc(n))
#> # A tibble: 157 x 2
#> author n
#> <chr> <int>
#> 1 Hadley Wickham 2458
#> 2 Winston Chang 650
#> 3 Kohske Takahashi 232
#> 4 Jean-Olivier Irisson 63
#> 5 Lionel Henry 50
#> 6 Thomas Lin Pedersen 47
#> 7 Kirill Müller 40
#> 8 Kara Woo 36
#> 9 Brian Diggs 27
#> 10 Jake Russ 20
#> # ... with 147 more rows
And top-ten visualized with ggplot2:
history_logs %>%
count(author) %>%
top_n(10, n) %>%
mutate(author = fct_reorder(author, n)) %>%
ggplot(aes(author, n)) +
geom_col(aes(fill = n), show.legend = FALSE) +
coord_flip() +
theme_minimal() +
ggtitle("ggplot2 authors with most commits") +
labs(x = NULL, y = "Number of commits", caption = "Post by @drsimonj")
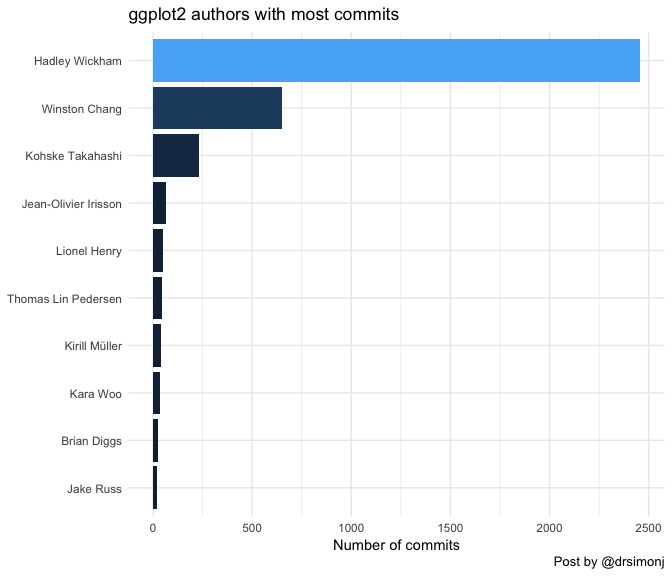
Not surprising to see Hadley Wikham topping the charts. Otherwise, the analysis options are pretty endless from here!
Part 3: Advanced Topics #
I’d like to touch on two advanced topics before leaving you to embark on astounding git repo analyses.
Git repo as a relational graph #
A git history is a relational structure where commits are nodes and connections between them are directed edges (from parent to child).
The code below converts our tidy data frame into a tidy relational structure made up of two data frames (nodes and edges) thanks to tidygraph (learn more from the package creator, Thomas Lin Pedersen, in blog posts like this).
# Convert commit to a factor (for ordering nodes)
history_logs <- history_logs %>%
mutate(commit = factor(commit))
# Nodes are the commits (keeping relevant info)
nodes <- history_logs %>%
select(-parents) %>%
arrange(commit)
# Edges are connections between commits and their parents
edges <- history_logs %>%
select(commit, parents) %>%
unnest(parents) %>%
mutate(parents = factor(parents, levels = levels(commit))) %>%
transmute(from = as.integer(parents), to = as.integer(commit)) %>%
drop_na()
# Create tidy directed graph object
git_graph <- tbl_graph(nodes = nodes, edges = edges, directed = TRUE)
git_graph
#> # A tbl_graph: 3946 nodes and 4371 edges
#> #
#> # A directed acyclic simple graph with 1 component
#> #
#> # Node Data: 3,946 x 5 (active)
#> datetime commit author subject branch
#> <chr> <fct> <chr> <chr> <int>
#> 1 2011-07-19 22:40:33 002e510d Kohske Takahashi remove style param… 4
#> 2 2008-07-05 20:00:50 0036ad7f Hadley Wickham HAcks to get tile … 1
#> 3 2010-02-05 10:25:26 0072cf4c Hadley Wickham Fix bug with empty… 1
#> 4 2013-12-02 13:51:05 008018cc Josef Fruehwald added stat_ellipse 9
#> 5 2010-12-23 10:22:36 00821913 Hadley Wickham Fix doc name 1
#> 6 2011-12-23 06:24:28 008312c0 Hadley Wickham Merge pull request… 1
#> # ... with 3,940 more rows
#> #
#> # Edge Data: 4,371 x 2
#> from to
#> <int> <int>
#> 1 3070 968
#> 2 1071 968
#> 3 3370 1071
#> # ... with 4,368 more rows
Using ggraph (another of Thomas’ awesome packages with more detailed info in posts like this) a default visualization could look something like this:
git_graph %>%
ggraph() +
geom_edge_link(alpha = .1) +
geom_node_point(aes(color = factor(branch)), alpha = .3) +
theme_graph() +
theme(legend.position = "none")
#> Using `nicely` as default layout

This looks cool but not right! A "manual" layout is needed for a linear visualisation of the git history (see the dplyr network for example).
For convenience, this is a template pipeline that will take the tidy graph object, ensure the proper layout is used, and create the basic plot:
ggraph_git <- . %>%
# Set node x,y coordinates
activate(nodes) %>%
mutate(x = datetime, y = branch) %>%
# Plot with correct layout
create_layout(layout = "manual", node.positions = as_tibble(activate(., nodes))) %>%
{ggraph(., layout = "manual") + theme_graph() + labs(caption = "Post by @drsimonj")}
Using this pipeline:
git_graph %>%
ggraph_git() +
geom_edge_link(alpha = .1) +
geom_node_point(aes(color = factor(branch)), alpha = .3) +
theme(legend.position = "none") +
ggtitle("Commit history of ggplot2")
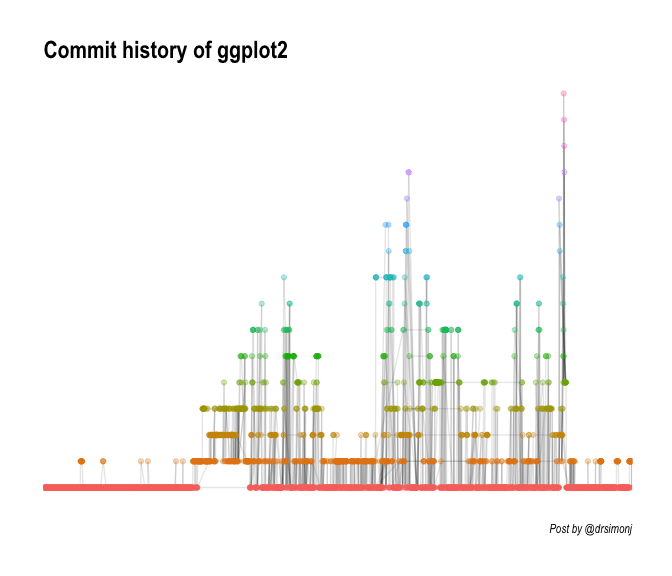
Much better! You can go crazy with how you’d like to visualise the repo. For example, here we filter on a specific date range:
git_graph %>%
activate(nodes) %>%
filter(datetime > "2015-11-01", datetime < "2016-08-01") %>%
ggraph_git() +
geom_edge_link(alpha = .1) +
geom_node_point(aes(color = factor(branch)), alpha = .3) +
theme(legend.position = "none") +
ggtitle("Git history of ggplot2",
subtitle = "2015-11 to 2016-08")

Here commits are highlighted for the top authors:
# 10 most-common authors
top_authors <- git_graph %>%
activate(nodes) %>%
as_tibble() %>%
count(author, sort = TRUE) %>%
top_n(10, n) %>%
pull(author)
# Plot
git_graph %>%
activate(nodes) %>%
filter(datetime > "2015-11-01", datetime < "2016-08-01") %>%
mutate(author = factor(author, levels = top_authors),
author = fct_explicit_na(author, na_level = "Other")) %>%
ggraph_git() +
geom_edge_link(alpha = .1) +
geom_node_point(aes(color = author), alpha = .3) +
theme(legend.position = "bottom") +
ggtitle("ggplot2 commits by author",
subtitle = "2015-11 to 2016-08")
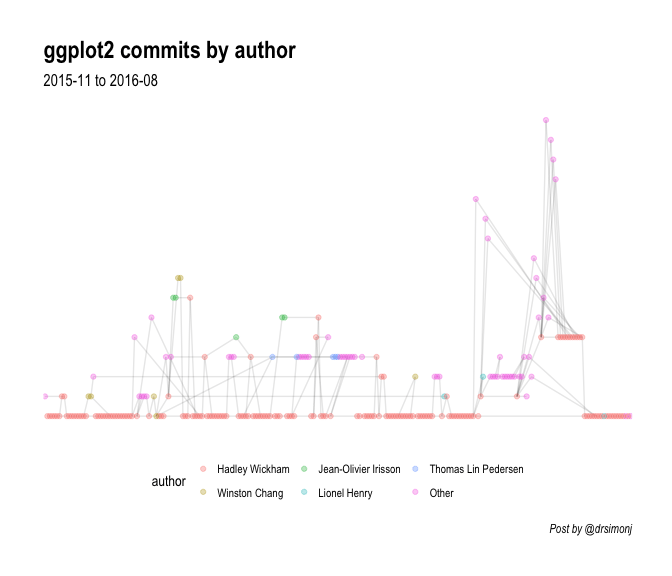
I hope this gives you enough to start having fun with these sorts of visualisations!
Text Mining Commit Messages #
Commit messages are simple but great material for tidy text-mining tools like the brilliant tidytext package, best learned from Text Mining with R: A Tidy Approach, by Julia Silge and David Robinson. Here are some examples using commit subjects to get you started.
Get commit subjects into a tidy format and remove stop words.
data(stop_words)
tidy_subjects <- history_logs %>%
unnest_tokens(word, subject) %>%
anti_join(stop_words)
#> Joining, by = "word"
tidy_subjects
#> # A tibble: 16,477 x 6
#> datetime commit parents author branch word
#> <chr> <fct> <list> <chr> <int> <chr>
#> 1 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 merge
#> 2 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 pull
#> 3 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 request
#> 4 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 2491
#> 5 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 tidyverse
#> 6 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 tidyeval
#> 7 2018-03-22 18:42:25 3c9c504f <chr [2]> Lionel Henry 1 facets
#> 8 2018-03-22 17:55:23 449bc039 <chr [1]> Lionel Henry 2 remove
#> 9 2018-03-22 17:55:23 449bc039 <chr [1]> Lionel Henry 2 dependency
#> 10 2018-03-22 17:55:23 449bc039 <chr [1]> Lionel Henry 2 plyr
#> # ... with 16,467 more rows
What are the ten most frequently used words?
tidy_subjects %>%
count(word) %>%
top_n(10, n) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col(aes(fill = n), show.legend = FALSE) +
coord_flip() +
theme_minimal() +
ggtitle("Most-used words in ggplot2 commit subjects") +
labs(x = NULL, y = "Word frequency", caption = "Post by @drsimonj")
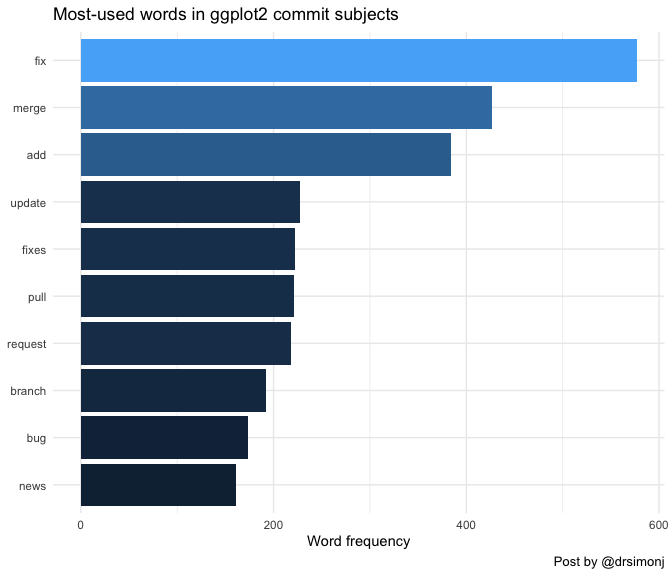
Or how about the words that most-frequently follow “fix”, the most-used word:
history_logs %>%
select(commit, author, subject) %>%
unnest_tokens(bigram, subject, token = "ngrams", n = 2) %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(word1 == "fix") %>%
anti_join(stop_words, by = c("word2" = "word")) %>%
count(word2, sort = TRUE)
#> # A tibble: 223 x 2
#> word2 n
#> <chr> <int>
#> 1 bug 57
#> 2 typo 37
#> 3 geom 11
#> 4 guides 11
#> 5 bugs 7
#> 6 doc 7
#> 7 boxplot 6
#> 8 axis 5
#> 9 documentation 5
#> 10 dumb 5
#> # ... with 213 more rows
Unsurprisingly, it seems like many of the commits involve fixing bugs and typos, as well as challenges with geoms and guides.
We’ve now covered more than enough for you to explore and analyse git repos in a tidy R framework. Don’t forget to share your findings with the world and let me know about it!
Sign off #
Thanks for reading and I hope this was useful for you.
For updates of recent blog posts, follow @drsimonj on Twitter, or email me at drsimonjackson@gmail.com to get in touch.
If you’d like the code that produced this blog, check out the blogR GitHub repository.