Label line ends in time series with ggplot2
@drsimonj here with a quick share on making great use of the secondary y axis with ggplot2 – super helpful if you’re plotting groups of time series!
Here’s an example of what I want to show you how to create (pay attention to the numbers of the right):
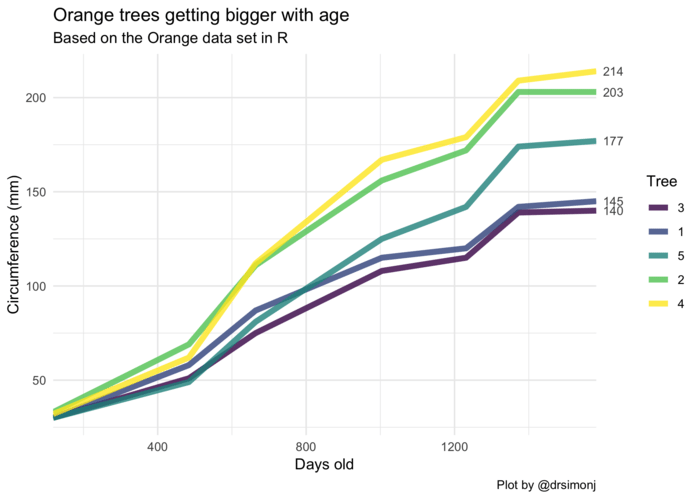
Setup
To setup we’ll need the tidyverse package and the Orange data set that comes with R. This tracks the circumference growth of five orange trees over time.
library(tidyverse)
d <- Orange
head(d)
> Grouped Data: circumference ~ age | Tree
> Tree age circumference
> 1 1 118 30
> 2 1 484 58
> 3 1 664 87
> 4 1 1004 115
> 5 1 1231 120
> 6 1 1372 142
Template code
To create the basic case where the numbers appear at the end of your time series lines, your code might look something like this:
You have a data set with:
- GROUP colum
- X colum