Plotting background data for groups with ggplot2
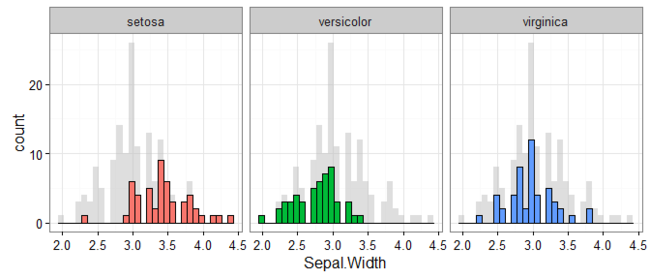
This tweet by mikefc alerted me to a mind-blowingly simple but amazing trick using the ggplot2 package: to visualise data for different groups in a facetted plot with all of the data plotted in the background. Here’s an example that we’ll learn to make in this post so you know what I’m talking about:
Credit where credit’s due
Before continuing, I’d be remiss for not mentioning that the origin of this ingenious suggestion is Hadley Wickham. The tip comes in his latest ggplot book, for which hardcopies are available online at places like Amazon, and the code and text behind it are freely available on Hadley’s Github at this repository.
Some motivating examples
Let’s start with some examples that explain just why I’m so excited about this trick. Consider wanting to plot the results shown in the example above. That is, for the iris data set (that comes with R), we want to plot a...