Pretty histograms with ggplot2
@drsimonj here to make pretty histograms with ggplot2!
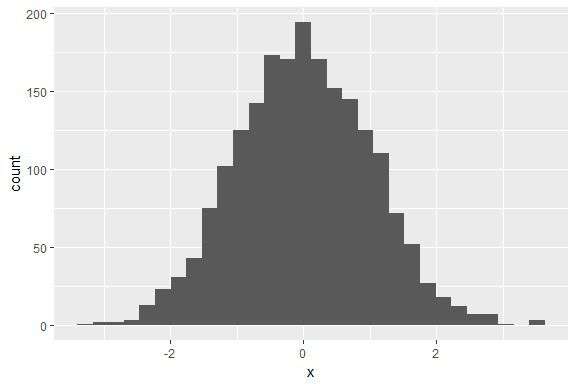
In this post you’ll learn how to create histograms like this:
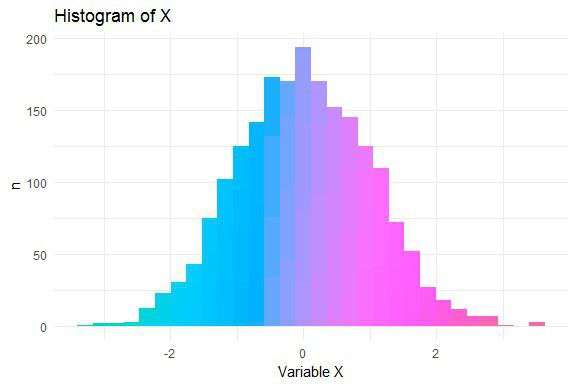
The data
Let’s simulate data for a continuous variable x in a data frame d:
set.seed(070510)
d <- data.frame(x = rnorm(2000))
head(d)
> x
> 1 1.3681661
> 2 -0.0452337
> 3 0.0290572
> 4 -0.8717429
> 5 0.9565475
> 6 -0.5521690
Basic Histogram
Create the basic ggplot2 histogram via:
library(ggplot2)
ggplot(d, aes(x)) +
geom_histogram()
Adding Colour
Time to jazz it up with colour! The method I’ll present was motivated by my answer to this StackOverflow question.
We can add colour by exploiting the way that ggplot2 stacks colour for different groups. Specifically, we fill the bars with the same variable (x) but cut into multiple categories:
ggplot(d, aes(x, fill = cut(x, 100))) +
geom_histogram()
What the…
Oh, ggplot2 has added a...